Zde je několik odkazů na (krátkou) historii Transformers:
Architektura Transformers byla zveřejněna v červnu 2017. Původní výzkum se soustředil především na problémy překladu. Tato publikace vedla k několika vlivným modelům:
června 2018: GPT, první předtrénovaný model pro jemné ladění, ukázal vysoce kvalitní výsledky pro mnoho úloh NLP.
října 2018: BERT, další velký předtrénovaný model, byl navržen tak, aby extrahoval přesnější obsah z vět (více se o tom dozvíme v další kapitole!)
února 2019: GPT-2, vylepšená (a větší) verze GPT, která nebyla okamžitě zveřejněna z etických důvodů
října 2019: DistilBERT, „destilovaná“ verze BERT, která je o 60 % rychlejší a o 40 % méně objemná, přesto si zachovává 97 % výkonu BERT
října 2019: BART a T5, dva velké modely, které navazují na architekturu klasického transformátoru
může 2020, GPT-3, ještě větší verze GPT-2, schopná dobře zvládat různé úkoly bez nutnosti dolaďování (tzv. učení s nulovým výstřelem)
Tento seznam není zdaleka úplný, má pouze upozornit na několik typů modelů transformátorů. Obecně lze transformátory rozdělit do tří typů:
- Modely podobné GPT (také často nazývané autoregresivní transformátory)
- Modely podobné BERT (také často nazývané automatické kódování transformátory (automatické kódování))
- modely typu BART/T5 (také často nazývané modely třídy sekvence-sekvence (sekvence-k-sekvenci, seq2seq))
Na tyto rodiny se podíváme podrobněji později.
Transformátory – jazykové modely
Všechny výše uvedené modely transformátorů (GPT, BERT, BART, T5 atd.) jsou vyškoleny jako jazykové modely. To znamená, že jsou školeni na velkém množství textu pomocí technik učení s vlastním dohledem. Učení vlastním tempem je metoda učení, při které se cíl učení automaticky vypočítává na základě vstupních dat. To znamená, že lidé by neměli označovat data!
Tento typ modelu implementuje statistické porozumění jazyku, ve kterém byl trénován, ale není příliš užitečný pro konkrétní praktické problémy. Z tohoto důvodu je základní předem trénovaný model podroben proceduře tzv přenos učení. Během tohoto procesu se model ladí na konkrétní pozorování, tzn. data označená člověkem pro konkrétní úkol.
Příkladem může být předpovídání dalšího slova ve větě na základě n předchozí slova. To se nazývá kauzální jazykové modelování, protože model závisí na minulých a současných slovech, ale ne na budoucích.
Další příklad – maskované jazykové modelování, který předpovídá maskované slovo ve větě.
Transformátory – velké modely
S výjimkou několika modelů (např. DistilBERT) je obecným přístupem k dosažení vysoké kvality zvětšení velikosti modelů a zvýšení množství trénovacích dat.

Bohužel trénování modelu, zvláště velkého, vyžaduje spoustu dat. To má za následek zvýšené časové a výpočetní nároky. To má dokonce dopad na životní prostředí, jak je vidět na grafu níže.
A to je jasná ukázka (velmi rozsáhlého) projektu vývoje modelu vedeného týmem vědomě snaží se snížit dopad přípravného školení na životní prostředí. Uhlíková stopa při provádění více experimentů za účelem získání lepších hyperparametrů bude ještě vyšší.
Představte si, že by pokaždé, když by výzkumná skupina, studentská organizace nebo společnost chtěla vycvičit modelku, udělali by to od nuly. To by vedlo k obrovským, zbytečným globálním nákladům!
To je důvod, proč je šíření jazykových modelů nanejvýš důležité: distribuce trénovaných vah a vytváření nových modelů na nich založených snižuje celkové výpočetní náklady a uhlíkovou stopu komunity.
Mimochodem, uhlíkovou stopu svých modelů můžete měřit pomocí několika nástrojů. Například integrovaný do Transformers ML CO2 Impact nebo Code Carbon. Chcete-li se o tom dozvědět více, můžete si přečíst tento blogový příspěvek, kde se zabýváme tím, jak vygenerovat soubor emise.csv obsahující prognózu emisí uhlíku během tréninku modelu, a také dokumentaci Transformers, která toto téma pokrývá.
Přestupový trénink
Předtrénink je proces trénování modelu od nuly: váhy modelu jsou náhodně inicializovány a poté začíná trénování bez předběžného nastavení.
Předškolení obvykle probíhá na velkých souborech dat a samotný proces může trvat několik týdnů.
Dodatečné školení (angl. jemné doladění), na druhou stranu je to trénink po jak byl model předtrénován. Pro další školení musíte nejprve vybrat předtrénovaný jazykový model a poté pokračovat v jeho školení na datech vašeho vlastního úkolu. Počkejte – proč nenatrénovat model okamžitě na datech pro konkrétní úlohu? Důvodů je několik:
Předtrénovaný model je již natrénován na datové sadě, která má mnoho podobností s předtréninkovou datovou sadou. Předtréninkový proces může využívat znalosti, které model získal během předtréninkového procesu (například v úkolech NLP bude předtrénovaný model rozumět statistickým zákonitostem jazyka, který ve svém úkolu používáte ).
Vzhledem k tomu, že předtrénovaný model již „viděl“ mnoho dat, další tréninkový proces vyžaduje k získání přijatelných výsledků méně dat.
Ze stejného důvodu trvá dosažení dobrých výsledků mnohem méně času.
Můžete například použít model předem natrénovaný v angličtině a poté jej trénovat na korpusu arXiv, výsledkem čehož je výzkumný model. Pro další školení bude vyžadováno pouze omezené množství dat: znalosti, které předtrénovaný model získal, jsou „přeneseny“ (provede přenos), odtud termín „přenos učení“.
Dodatečné školení modelu tedy vyžaduje méně času, dat, finančních a ekologických nákladů. Je také rychlejší a snazší procházet různými předtréninkovými schématy, protože vyžaduje méně úsilí než úplný předtrénink.
Tento proces také poskytne lepší výsledky než trénování od nuly (pokud nemáte mnoho dat), takže byste se měli vždy snažit použít předem trénovaný model – model, který je co nejblíže danému úkolu – a poté jej znovu trénovat .
Obecná architektura
V této části se podíváme na obecnou architekturu modelu transformátoru. Nedělejte si starosti, pokud některým pojmům nerozumíte; Dále jsou zde podrobné části věnované každé z komponent.
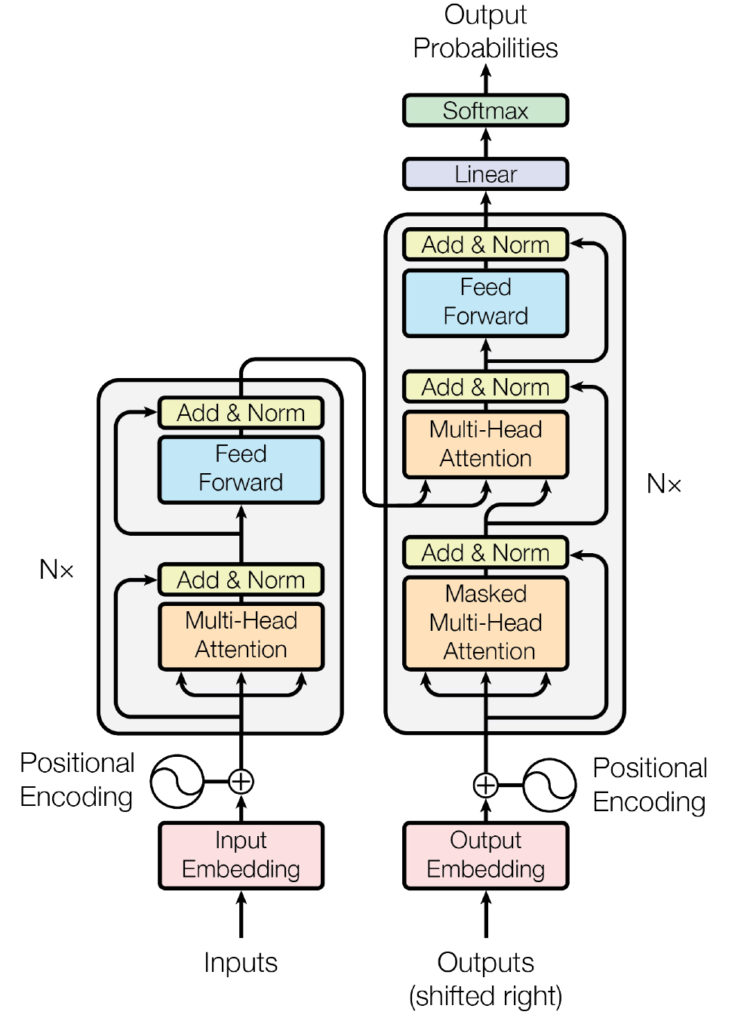
Model se skládá ze dvou bloků:
- Kodér (vlevo) (Encoder): kodér přijímá vstupní data a vytváří jejich reprezentaci (formuje prvky). To znamená, že cílem modelu je „porozumět“ vstupním datům.
- Dekodér (vpravo) (anglický dekodér): Dekodér používá reprezentace (vlastnosti) kodéru s dalšími vstupními daty k vytvoření požadované sekvence. To znamená, že cílem modelu je generovat výstupní data.
Každou z těchto částí lze použít samostatně, záleží na úkolu:
- Modelové kodéry: Užitečné pro úkoly, které vyžadují pochopení vstupních dat, jako je klasifikace vět a rozpoznávání pojmenovaných entit.
- Dekódovací modely: Užitečné pro generativní úlohy, jako je generování textu.
- Modely kodér-dekodér nebo modely seq2seq: Užitečné při generativních úlohách, které vyžadují vstupní data. Například: překlad nebo automatická sumarizace textu.
Tyto architektury prozkoumáme podrobněji v následujících částech.
Vrstva pozornosti
Klíčovou vlastností transformátorů je přítomnost v architektuře speciální vrstvy tzv vrstva pozornosti. Článek, ve kterém byla architektura transformátoru poprvé představena, se jmenuje „Attention Is All You Need“! Podrobnosti o této vrstvě prozkoumáme později. V tuto chvíli budeme formulovat mechanismus jeho fungování následovně: vrstva pozornosti pomáhá modelu „dávat pozor“ na některá slova ve větě zadané jako vstup a jiná slova v té či oné míře ignorovat. A to se děje v procesu analýzy každého slova.
Abychom to uvedli do kontextu, zvažte problém překladu textu z angličtiny do francouzštiny. U věty „Líbí se vám tento kurz“ bude muset model také vzít v úvahu sousední slovo „Vy“, aby získal správný překlad slova „jako“, protože ve francouzštině se sloveso „jako“ konjuguje odlišně v závislosti na předmět. Zbytek věty je však pro překlad tohoto slova zbytečný. Ve stejném duchu budete muset při překladu „jako“ věnovat pozornost také slovu „kurz“, protože „toto“ se překládá odlišně v závislosti na tom, zda je související podstatné jméno mužského nebo ženského rodu. Opět platí, že pro překlad „toto“ nezáleží na dalších slovech ve větě. U složitějších vět (a složitějších gramatických pravidel) bude muset model věnovat zvláštní pozornost slovům, která mohou být dále ve větě, aby správně přeložil každé slovo.
Stejný koncept platí pro jakýkoli problém zpracování přirozeného jazyka: slovo samo o sobě má nějaký význam, ale význam velmi často závisí na kontextu, kterým může být slovo (nebo slova) obklopující hledané slovo.
Nyní, když jste obeznámeni s myšlenkou pozornosti obecně, pojďme se blíže podívat na architekturu celého Transformeru.
Počáteční architektura
Architektura Transformer byla původně navržena pro překlad. Během školení kodér přijímá vstup (věty) v určitém jazyce a dekodér přijímá stejné věty v požadovaném cílovém jazyce. V kodéru mohou vrstvy pozornosti používat všechna slova ve větě (protože, jak jsme právě viděli, překlad daného slova může záviset na tom, co ve větě následuje za ním a před ním). Dekodér zase funguje sekvenčně a může věnovat pozornost pouze slovům ve větě, která již přeložil (tedy pouze slovům před aktuálně vygenerovaným slovem). Například, když jsme předpověděli první tři slova přeloženého cíle, předáme je dekodéru, který pak použije veškerý vstup kodéru, aby se pokusil předpovědět čtvrté slovo.
Pro urychlení procesu během trénování (když má model přístup k cílovým větám) je dekodéru přidělena celá cílová věta, ale nesmí používat budoucí slova (pokud měl přístup ke slovu na pozici 2 při pokusu předpovědět slovo na pozici 2, úkol selže komplikovaně!). Například při pokusu o předpovědi čtvrtého slova bude mít vrstva pozornosti přístup pouze ke slovům na pozicích 1 až 3.
Původní architektura Transformeru vypadala takto, s kodérem vlevo a dekodérem vpravo:
Všimněte si, že první vrstva pozornosti v bloku dekodéru věnuje pozornost všem (minulým) vstupům dekodéru, zatímco druhá vrstva pozornosti používá výstupy kodéru. Tímto způsobem může získat přístup k celé vstupní větě, aby co nejlépe předpověděl aktuální slovo. To je velmi užitečné, protože různé jazyky mohou mít gramatická pravidla, která umisťují slova v různém pořadí, nebo nějaký kontext poskytnutý ve větě daleko od aktuálního slova. Kontext může být nápomocný při určování nejlepšího překladu daného slova.
Pozor maska lze také použít v kodéru/dekodéru, aby model ignoroval některá speciální slova – například speciální neexistující výplňové slovo používané k tomu, aby všechny vstupy měly stejnou délku při seskupování vět.
Architektury a kontrolní body
Když se ponoříte do Transformers, narazíte na pojmy architektura и kontrolní body (anglicky checkpoints) ve smyslu modely. Tyto výrazy mají různé významy:
architektura – kostra modelu – vrstvy, spojení a operace, které se v modelu provádějí. Kontrolní bod – váhy modelu, které lze načíst pro konkrétní architekturu. model je zastřešující termín, který může znamenat architekturu i váhy pro konkrétní architekturu. V tomto kurzu budeme termíny používat přesněji architektura и kontrolní bod, pokud to bude důležité pro lepší pochopení.
Například BERT je architektura a bert-base-cased, sada vah připravená společností Google pro první vydání BERT, je kontrolním bodem. Můžete však říci jak „model BERT“, tak „model bert-base-cased“.
Transformátory jsou relativně novým typem neuronové sítě zaměřené na řešení sekvencí se snadným zpracováním závislostí dlouhého dosahu. Jedná se o dnes nejpokročilejší techniku v oblasti přirozeného zpracování řeči (NLP).
S jejich pomocí můžete překládat text, psát poezii a články a dokonce generovat počítačový kód.Na rozdíl od rekurentních neuronových sítí (RNN) transformátory nezpracovávají sekvence v pořadí. Pokud je například zdrojová data text, nemusí po zpracování začátku zpracovávat konec věty. Díky tomu lze takovou neuronovou síť paralelizovat a trénovat mnohem rychleji.
Kdy se objevily?
Transformers byly poprvé popsány inženýry z Google Brain v práci „Attention Is All You Need“ v roce 2017.
Jedním z hlavních rozdílů od stávajících metod zpracování dat je to, že vstupní sekvenci lze přenášet paralelně, takže lze efektivně využít GPU a také zvýšit rychlost tréninku.
Proč jsou potřeba transformátory?
Až do roku 2017 používali inženýři hluboké učení k porozumění textu pomocí rekurentních neuronových sítí.
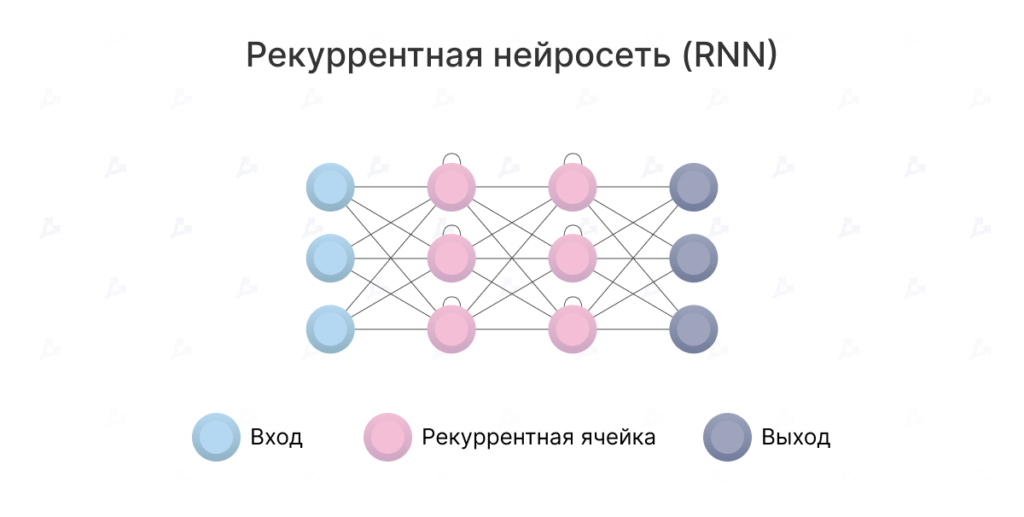
Řekněme, že při překladu věty z angličtiny do ruštiny vezme RNN jako vstup anglickou větu, zpracuje slova jedno po druhém a poté postupně vypíše jejich ruské protějšky. Klíčovým slovem je zde „konzistentní“. Pořadí slov v jazyce je důležité a nelze je jednoduše míchat dohromady.
To je místo, kde RNN čelí řadě výzev. Nejprve se snaží zpracovat velké sekvence textu. Než se přesunou na konec odstavce, „zapomněli“ obsah začátku. Například model překladu založený na RNN může mít potíže se zapamatováním pohlaví dlouhého textového objektu.
Za druhé, RNN je obtížné trénovat. Je známo, že jsou náchylné k takzvanému problému mizejícího/explodujícího gradientu.
Za třetí, zpracovávají slova sekvenčně, opakující se neuronová síť je obtížně paralelizovatelná. To znamená, že není možné urychlit trénink použitím více GPU. Nelze jej tedy trénovat na velkém množství dat.
Jak Transformers fungují?
Hlavními součástmi transformátorů jsou kodér a dekodér.
Kodér bere příchozí informace (jako je text) a převádí je na vektor (množinu čísel). Dekodér ji zase dešifruje v podobě nové sekvence (například odpovědi na otázku) slov v jiném jazyce – podle toho, pro jaký účel byla neuronová síť vytvořena.
Další inovace za Transformers se skládají ze tří hlavních konceptů:
- Polohové kodéry (Poziční kódování);
- Pozornost;
- Sebepozornost.
Začněme tím prvním – pozičními kodéry. Řekněme, že potřebujete přeložit text z angličtiny do ruštiny. Standardní modely RNN „rozumí“ pořadí slov a zpracovávají je postupně. To však ztěžuje paralelizaci procesu.
Polohové kodéry tuto bariéru překonávají. Cílem je vzít všechna slova ve vstupní sekvenci – v tomto případě anglickou větu – a ke každému přidat číslo v jeho pořadí. Takže napájíte síť v této sekvenci:
[(“Červená”, 1), (“liška”, 2), (“skáče”, 3), (“přes”, 4), (“líná”, 5), (“pes”, 6)]
Koncepčně to lze chápat jako přesunutí břemene porozumění slovosledu ze struktury neuronové sítě na data samotná.
Nejprve, než se transformátory poučí z jakýchkoli informací, nevědí, jak tato polohová kódování interpretovat. Ale jak model vidí stále více příkladů vět a jejich kódování, učí se je efektivně používat.
Výše uvedená struktura je příliš zjednodušená – autoři původní studie použili funkce sinus, aby přišli s pozičním kódováním spíše než jednoduchá celá čísla 1, 2, 3, 4, ale myšlenka je stejná. Ukládáním slovosledu jako dat spíše než struktury se neuronová síť snáze trénuje.
Pozornost je struktura neuronové sítě zavedená do kontextu strojového překladu v roce 2015. Abychom tomuto konceptu porozuměli, podívejme se na původní článek.
Představme si, že potřebujeme přeložit frázi do francouzštiny:
“Dohoda o Evropském hospodářském prostoru byla podepsána v srpnu 1992.”
Francouzský ekvivalent výrazu je:
“L’accord sur la zone économique européenne a été signé en août 1992.”
Nejhorší možností překladu je přímo vyhledávat analogy slov z angličtiny ve francouzštině, jeden po druhém. To nelze provést z několika důvodů.
Nejprve jsou některá slova ve francouzském překladu obrácena:
“Evropský hospodářský prostor” против “La zone économique européenne”.
Za druhé, francouzský jazyk je bohatý na genderová slova. Aby odpovídal ženskému objektu “la zóna”, přídavná jména “Economique” и “evropský” musí být také umístěn v ženském rodě.
Pozornost pomáhá takovým situacím předcházet. Jeho mechanismus umožňuje textovému modelu „podívat se“ na každé slovo ve zdrojové větě, když se rozhoduje, jak je přeložit. To dokazuje vizualizace z původního článku:

Jedná se o druh tepelné mapy, která ukazuje, na co se model „dívá“, když překládá každé slovo ve francouzské větě. Jak byste očekávali, když model vydá slovo “evropský”, do značné míry zohledňuje obě vstupní slova − “Evropský” и “Hospodářský”.
Tréninkové údaje vám pomohou naučit se, na která slova „dávat pozor“ v každém kroku. Pozorováním tisíců anglických a francouzských vět se algoritmus učí vzájemně závislé slovní druhy. Učí se brát v úvahu gender, pluralitu a další gramatická pravidla.
Modul pozornosti byl od svého objevení v roce 2015 nesmírně užitečným nástrojem pro zpracování přirozeného jazyka, ale ve své původní podobě byl používán ve spojení s rekurentními neuronovými sítěmi. Inovace dokumentu z roku 2017 o Transformerech byla tedy částečně zaměřena na úplné odstranění RNN. Proto se dokument z roku 2017 jmenuje „Pozornost je vše, co potřebujete“.
Poslední částí Transformers je obrat pozornosti nazývaný „sebepozornost“.
Pokud pozornost pomáhá zarovnat slova při překladu z jednoho jazyka do druhého, pak sebepozornost umožňuje modelu pochopit význam a vzorce jazyka.
Zvažte například tyto dvě věty:
„Nikolaj ztratil klíč od auta“
„Jeřábový klíč míří na jih“
Slovo “klíč” zde znamená dvě velmi odlišné věci, které my, lidé, známe situaci, můžeme snadno rozlišit jejich význam. Vlastní pozornost umožňuje neuronové síti porozumět slovu v kontextu slov kolem něj.
Takže když model zpracuje slovo “klíč” v první větě může věnovat pozornost “auta” a pochopte, že mluvíme o speciálně tvarované kovové tyči pro zámek, a ne o něčem jiném.
Ve druhé větě si modelka může dát pozor na slova “jeřáb” и “jižní”přisuzovat “klíč” do hejna ptáků. Vlastní pozornost pomáhá neuronovým sítím rozlišovat slova, označovat části vět, učit se sémantické role a mnoho dalšího.
Kde se používají?
Transformátory byly původně umístěny jako neuronová síť pro zpracování a pochopení přirozeného jazyka. Za čtyři roky od svého zavedení si získaly oblibu a objevily se v nejrůznějších službách, které denně využívají miliony lidí.
Jedním z nejjednodušších příkladů je jazykový model BERT společnosti Google, vyvinutý v roce 2018.
Dne 25. října 2019 technologický gigant oznámil zahájení používání algoritmu v anglické verzi vyhledávače ve Spojených státech. O měsíc a půl později společnost rozšířila seznam podporovaných jazyků na 70, včetně ruštiny, ukrajinštiny, kazaštiny a běloruštiny.
Původní anglický model byl trénován na datovém souboru BooksCorpus s 800 miliony slov a článků z Wikipedie. Základní BERT obsahoval 110 milionů parametrů a rozšířený – 340 milionů.
Dalším příkladem populárního jazykového modelu založeného na transformátoru je GPT (Generative Pre-trained Transformer) OpenAI.
Dnes je nejnovější verzí modelu GPT-3. Byl trénován na datové sadě 570 GB a počet parametrů byl 175 miliard, což z něj dělá jeden z největších jazykových modelů.
GPT-3 může generovat články, odpovídat na otázky, být použit jako základ pro chatboty, provádět sémantické vyhledávání a vytvářet krátké úryvky z textů.
Na základě GPT-3 byl také vyvinut asistent AI pro automatické psaní kódu GitHub Copilot. Je založen na speciální verzi GPT-3 Codex AI, trénované na datové sadě řádků kódu. Vědci již odhadli, že od jeho vydání v srpnu 2021 bylo 30 % nového kódu na GitHubu napsáno pomocí Copilota.
Kromě toho se transformace stále častěji používají ve službách Yandex, například ve vyhledávání, zprávách a překladačích, produktech Google, chatovacích botech atd. A společnost Sber vydala vlastní modifikaci GPT, vyškolenou na 600 GB ruskojazyčných textů.
Jaké jsou vyhlídky transformátorů?
Dnes je potenciál transformátorů stále neodhalený. Už se dobře osvědčily při zpracování textu, ale v poslední době se o tomto typu neuronových sítí uvažuje i v jiných úlohách, jako je počítačové vidění.
Na konci roku 2020 vykazovaly modely CV dobré výsledky v některých oblíbených benchmarcích, jako je detekce objektů na datové sadě COGO nebo klasifikace obrázků na ImageNet.
V říjnu 2020 zveřejnili vědci z Facebook AI Research článek, ve kterém popsali model Data-efficient Image Transformers (DeiT) založený na transformátorech. Podle autorů našli způsob, jak trénovat algoritmus bez obrovského souboru označených dat, a získali vysokou přesnost rozpoznávání obrazu – 85 %.
V květnu 2021 představili odborníci z Facebook AI Research open-source algoritmus počítačového vidění DINO, který automaticky segmentuje objekty na fotografiích a videích bez ručního označování. Je také založen na transformátorech a přesnost segmentace dosáhla 80 %.
Kromě NLP tak transformátory stále častěji nacházejí uplatnění i v jiných úlohách.
Jaké hrozby představují transformátory?
Kromě zjevných výhod představují transformátory v oblasti NLP řadu hrozeb. Tvůrci GPT-3 opakovaně uvedli, že neuronová síť může být použita k masivním útokům spamu, obtěžování nebo dezinformacím.
Kromě toho je jazykový model zaujatý vůči určitým skupinám lidí. I když vývojáři snížili toxicitu GPT-3, stále nejsou připraveni zpřístupnit tento nástroj širšímu okruhu vývojářů.
V září 2020 zveřejnili vědci z Middlebury College zprávu o rizicích společenské radikalizace spojené s šířením velkých jazykových vzorů. Poznamenali, že GPT-3 vykazuje „významná zlepšení“ při vytváření extremistických textů ve srovnání s jeho předchůdcem GPT-2.“
Jeden z „otců hlubokého učení“, Yann LeCun, také tuto technologii kritizoval. Řekl, že mnohá očekávání ohledně schopností velkých jazykových modelů jsou nerealistická.
„Pokoušet se postavit inteligentní stroje pomocí škálování jazykových modelů je jako stavět letadla k letu na Měsíc. Můžete překonat výškové rekordy, ale cesta na Měsíc bude vyžadovat úplně jiný přístup,“ napsal LeCun.















